
1. AI trading bot--Fetching data from Binance
This blog post is the first in the series of building an AI (Artificial intelligence) crypto trading bot, the chambot.
The assumption we make here is that you are already familiar with how the stock, crypto, or foreign exchange work. If we pick crypto as our financial instrument without loss of generality, you will notice that the price of crypto is always moving up and down. This movement is risky for an investor who might incur huge losses if the crypto price drops significantly after buying at a higher price. On the other hand, traders that buy and sell crypto try to use these fluctuations in crypto prices to their advantage.
They buy when the price is low, and sell when the price is high. The real question is when do you buy (hold a position) and when do you sell (leave a position). Many traders spend hours staring at the computer screen waiting for the right moment to act. In a couple of blog posts, I will show how to build a robot that automatically buys at the low and sell at a high price. This bot is called the chambot and uses AI for smart buying and selling. We will need data to do this, AI models need that has predictor variables and a target. Our workflow will reflect this.
Here is the work flow:
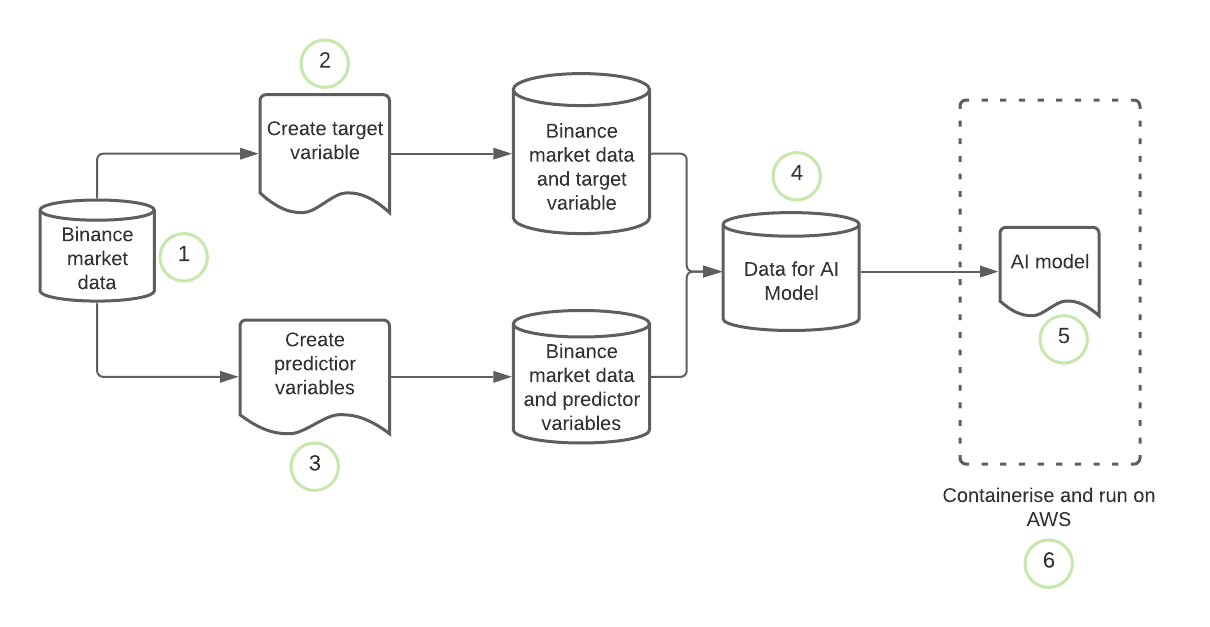
These are the steps we will take:
- Fetch market data from Binance
- Create a target variable
- Create predictor variables
- Merge the predictor variables and the target variable to form a dataset that will be used to train an AI model
- Train AI model
- Put the model in production on AWS to start buying and selling crypto and making huge profits.
This short blog post is based on point 1., i.e., fetching data from binance, I will show you how to fetch data from Binance and store it as a .csv.
Make sure your requirements.txt contains the following modules.
import requests
import json
import pandas as pd
import numpy as np
import datetime as dt
from binance.client import Client
import time
from datetime import timedelta, datetime
import math
from dateutil import parser
import os.path
import config ### this config file should contain your API keys API_KEY_BINANCE and API_SECRET_BINANCE
### ofcourse I will not put mine here :)
We will define two important functions that will fetch data and download the data. We will set the batch_size and the binsizes, as the name implies these are the batch size and the bin sizes. We will also create a binance client for subsequent use.
binsizes = {"1m": 1, "15m": 15, "1h": 60, "1d": 1440}
batch_size = 750
result = pd.DataFrame(binsizes,index=[0])
binance_client = Client(api_key=config.API_KEY_BINANCE,
api_secret=config.API_SECRET_BINANCE)
print(result.to_markdown())
| | 1m | 15m | 1h | 1d |
|---:|-----:|------:|-----:|-----:|
| 0 | 1 | 15 | 60 | 1440 |
## FUNCTIONS
def minutes_of_new_data(symbol, kline_size, data, source):
if len(data) > 0: old = parser.parse(data["timestamp"].iloc[-1])
elif source == "binance": old = datetime.strptime('1 Jan 2017', '%d %b %Y')
# elif source == "bitmex": old = bitmex_client.Trade.Trade_getBucketed(symbol=symbol, binSize=kline_size, count=1, reverse=False).result()[0][0]['timestamp']
if source == "binance": new = pd.to_datetime(binance_client.get_klines(symbol=symbol, interval=kline_size)[-1][0], unit='ms')
# if source == "bitmex": new = bitmex_client.Trade.Trade_getBucketed(symbol=symbol, binSize=kline_size, count=1, reverse=True).result()[0][0]['timestamp']
return old, new
def get_all_binance(symbol, kline_size, save = False):
filename = '%s-%s-data.csv' % (symbol, kline_size)
if os.path.isfile(filename): data_df = pd.read_csv(filename)
else: data_df = pd.DataFrame()
oldest_point, newest_point = minutes_of_new_data(symbol,
kline_size,
data_df,
source = "binance")
delta_min = (newest_point - oldest_point).total_seconds()/60
available_data = math.ceil(delta_min/binsizes[kline_size])
if oldest_point == datetime.strptime('1 Jan 2017', '%d %b %Y'):
print(f'Downloading all available {kline_size} data for {symbol}. Be patient..!')
else:
print(f'Downloading {delta_min} minutes of new data available for {symbol}, i.e. {available_data} instances of {kline_size} data.')
klines =( binance_client.get_historical_klines(symbol, kline_size, oldest_point.strftime("%d %b %Y %H:%M:%S"), newest_point.strftime("%d %b %Y %H:%M:%S")))
data = pd.DataFrame(klines, columns = ['timestamp',
'open', 'high', 'low',
'close', 'volume', 'close_time',
'quote_av', 'trades',
'tb_base_av',
'tb_quote_av', 'ignore' ])
data['timestamp'] = pd.to_datetime(data['timestamp'], unit='ms')
if len(data_df) > 0:
temp_df = pd.DataFrame(data)
data_df = data_df.append(temp_df)
else:
data_df = data
data_df.set_index('timestamp', inplace=True)
if save:
data_df.to_csv(f'{filename}')
print('All caught up..!')
return data_df
USDT is a stable crypto currency that mimics the US dollar in the crypto world. Often it is tractable if you trade other volatile crypto currency like the Ethereum (ETH) with USDT. So we will first grab all X-USDT pairs from Binance. X stands for any crypto currency.
tickers = requests.get('https://www.binance.com/api/v1/ticker/allPrices').text
tickers = pd.DataFrame(json.loads(tickers))['symbol'].values
tickers = tickers[[tk.find('USDT') not in [0,-1] for tk in tickers]]
tickers[0:20]
array(['BTCUSDT', 'ETHUSDT', 'BNBUSDT', 'BCCUSDT', 'NEOUSDT', 'LTCUSDT',
'QTUMUSDT', 'ADAUSDT', 'XRPUSDT', 'EOSUSDT', 'TUSDUSDT',
'IOTAUSDT', 'XLMUSDT', 'ONTUSDT', 'TRXUSDT', 'ETCUSDT', 'ICXUSDT',
'VENUSDT', 'NULSUSDT', 'VETUSDT'], dtype=object)
We can now loop through the tickers list and download the data for all XUSDT pairs. That will take quite sometime. To download the data for a single group we do as follows:
tickers=['ETHUSDT']
for symbol in tickers:
df = get_all_binance(symbol, '15m', save = True)
Downloading 15.0 minutes of new data available for ETHUSDT, i.e. 1 instances of 15m data.
All caught up..!
Hope fully everything has worked fine. Let’s visualise the data that was downloaded:
print(df.head().to_markdown())
| timestamp | open | high | low | close | volume | close_time | quote_av | trades | tb_base_av | tb_quote_av | ignore |
|:--------------------|-------:|-------:|-------:|--------:|---------:|--------------:|-----------:|---------:|-------------:|--------------:|---------:|
| 2017-08-17 04:00:00 | 301.13 | 301.13 | 298 | 298 | 5.80167 | 1502943299999 | 1744.77 | 22 | 5.48392 | 1649.45 | 46528.3 |
| 2017-08-17 04:15:00 | 298 | 300.8 | 298 | 299.39 | 31.4407 | 1502944199999 | 9396.92 | 26 | 12.1171 | 3625.17 | 46537.3 |
| 2017-08-17 04:30:00 | 299.39 | 300.79 | 299.39 | 299.6 | 52.9358 | 1502945099999 | 15851.1 | 39 | 28.3816 | 8499.79 | 46678.9 |
| 2017-08-17 04:45:00 | 299.6 | 302.57 | 299.6 | 301.61 | 35.4907 | 1502945999999 | 10692 | 42 | 34.5811 | 10419 | 47039.7 |
| 2017-08-17 05:00:00 | 301.61 | 302.57 | 300.95 | 302.01 | 81.6924 | 1502946899999 | 24620.7 | 52 | 80.2634 | 24189.8 | 47181.9 |
In subsequent blog posts, we will start building the chambot. Do not miss to be part of this exciting journey.